
Large language models (LLMs) that generate code are nowadays common. Since a couple of weeks, VS Code has an agent mode that performs multi-step coding tasks.
I was actively involved in web development roughly 20–25 years ago, when CGI, Perl, and early versions of PHP were popular. I have no idea how modern web development actually works. I always had some projects in mind that I wanted to create, but I never had the time to dig into one of the modern JavaScript frameworks like React. GitHub Copilot now seems like a way to create (web) applications just by describing the requirements (i.e., vibe coding) for an entire application.
This post describes my experience building a PostgreSQL query plan explorer using React and VS Code in two evenings—without writing a single line of code myself.
When I started with web development, building web applications was quite simple. You had HTML, the first version of CSS, some software, and the Common Gateway Interface (CGI) standard. To build a dynamic website, you just wrote plain HTML to stdout, like:
#!/usr/bin/perl
print "Content-type: text/html\n\n";
print "<html><head></head><body>Hello World</body></html>\n";
Since that time, the internet has evolved. CSS became increasingly popular, and I switched to PHP for web development. JavaScript, AJAX, and further technologies have changed the way websites work. In my career, I developed mostly backend components and switched to database internals after I finished university. So, I lost track of how modern web applications work.
In 2020, I worked in a management role and led a team of web developers. I learned a bit about recent technologies like React, GraphQL, and Node.js, but never wrote code myself. However, since then, I have wanted to build a modern web application to understand how this works today. But I never had enough time to look deeper into any of these technologies.
The moment the agent mode for GitHub Copilot was released, it became clear to me that I wanted to challenge myself and see if I could build a modern web application without writing a single line of code—just by knowing the requirements, knowing which technologies can be used, and relying on 25-year-old knowledge about web development.
The Project
Since I spend most of my day with database internals, it was clear that I wanted to build something DBMS-related. A few weeks ago, a friend of mine drew my attention to Picasso.
The Picasso database query optimizer visualizer, Jayant R. Haritsa, Proceedings of the VLDB Endowment, Volume 3, Issue 1-2, September 2010
Picasso Database Query Optimizer Visualizer
The Picasso database query optimizer visualizer creates a multi-dimensional search space and executes a database query with different parameters from this search space to determine the query plan used by the database system. The resulting query plans (e.g., an index scan and a full table scan) are fingerprinted and plotted in an output graph. Similar plans are shown with the same color. Thus, the tool visualizes the query plans used and their distribution, generating images from that information.
Plan Explorer
The idea was to build a tool similar to Picasso using React as a static website. The required PostgreSQL installation to execute SQL queries and run the query optimizer can be embedded directly into the browser using PGlite to get a standalone app without any need for a database server.
PGlite is a WASM (WebAssembly – bytecode that is directly loaded and executed in the browser) build of PostgreSQL that can be loaded and executed in any WASM-capable browser (which is supported by most browsers these days).
Query Plans in PostgreSQL
In PostgreSQL, you can get the query plan used by prefixing a query with EXPLAIN. If the keyword JSON is added as an option, the returned query plan is in JSON format, which is useful for processing the query plans with JavaScript.
For example, if you have the following table structure:
CREATE TABLE data(key integer, value text);
INSERT INTO data (key, value) SELECT i, i::text FROM generate_series(1, 100000) i;
CREATE INDEX ON data(key);
And you perform a SELECT statement on the table with the following WHERE clause key > ...
SELECT * FROM data WHERE key > ...;
PostgreSQL could use:
- An index scan to get the tuples that qualify.
- Or a full table scan and apply the filter on each of the scanned tuples.
The query optimizer determines the fastest query plan. When the query returns many tuples, the index scan is very costly. The index structure has to be traversed, and the referenced tuples have to be read from the table. Therefore, a lot of random I/O is performed, and traversing the index also adds overhead. If the query returns a large fraction of the table, it could be faster to perform a full table scan and apply a filter condition to each of the tuples.
In contrast, if only a small fraction of the table is returned by the query (i.e., the selectivity of the predicate in the WHERE clause is low), the overhead added by the index scan is less than applying the filter condition to all tuples. So, it is beneficial to use the index.
However, there is no easy way to determine when this change between the two query plans will happen. This tool will run the query with different WHERE clauses to answer this question. The example section
shows how this decision will look for a concrete query.
Tool Features
So, the main tasks of the tool are:
- Iterating over a one- or two-dimensional search space.
- Letting PGlite generate the query plan for each parameter combination of the search space.
- Fingerprinting the returned query plans and finding similar query plans (i.e., plans with the same structure).
- Generating a clear visualization from the gathered data.
Using GitHub Copilot running in agent mode and GPT 4.1, I was able to build the desired tool in two evenings (roughly 2 × 2.5 hours) and a few small corrections in the days afterwards. I described the requirements (e.g., “the user should be able to determine a one or two-dimensional search space”, “dimension 1 of the search space should be optional”, “the tool should have a modern UI”).
The tool looks like this:
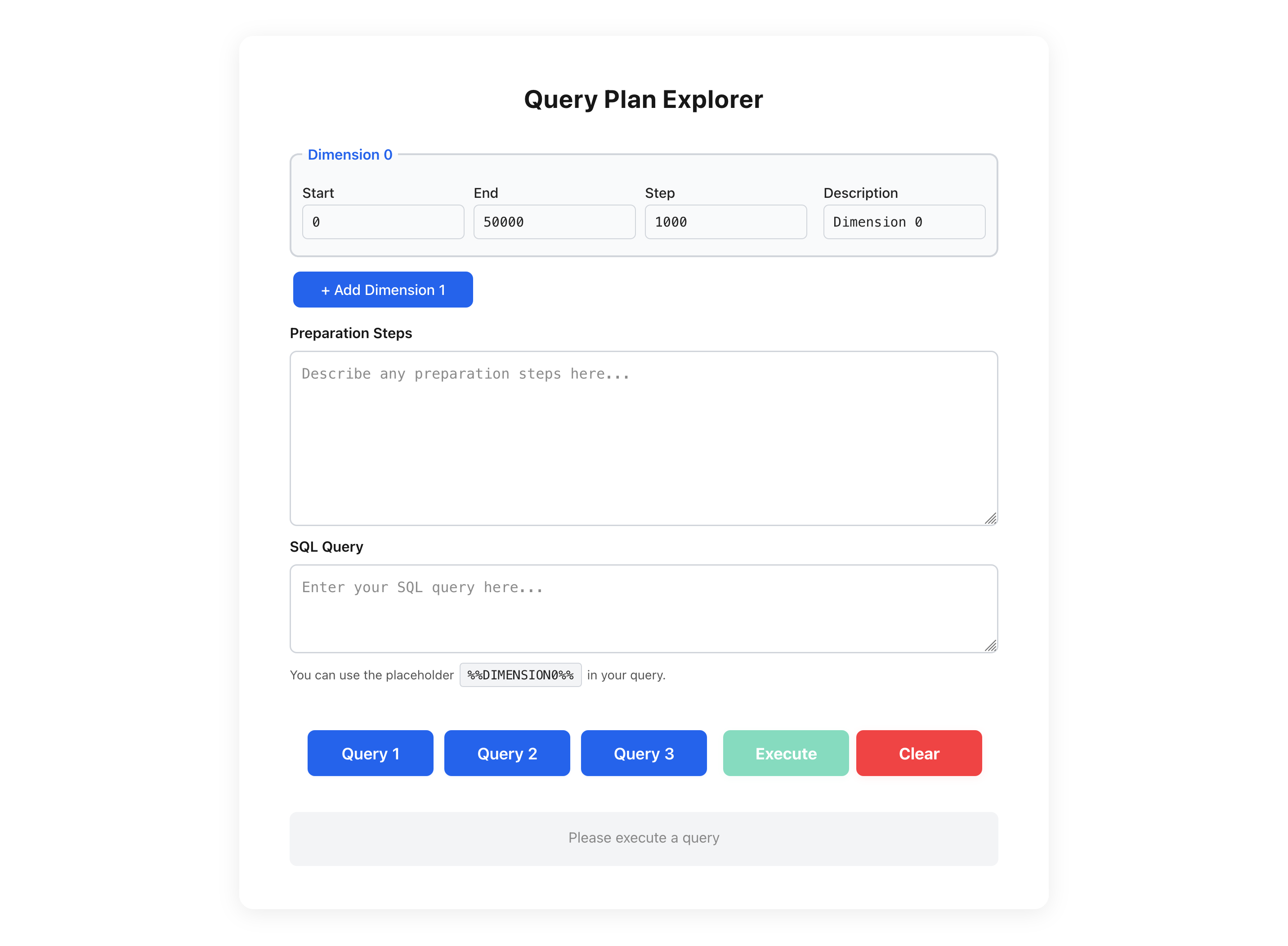
In the upper part of the tool, up to two dimensions, ranges, and steps can be defined. These describe the one- or two-dimensional search space that should be iterated by the tool. Afterwards, preparation steps to set up the database can be defined (e.g., creating tables and filling data). Then, the actual query with placeholders (%%DIMENSION0%% for the value of the first dimension and %%DIMENSION1%% for the value of the second dimension) can be defined.
A build of the tool can be found at https://jnidzwetzki.github.io/planexplorer/ if you want to try it yourself.
Example Query Plans
The tool provides useful insights into the decisions made by the query planner. In this section, the tool output for three different queries is discussed.
Select Using a Table Scan or an Index
In the query plan section, the case that PostgreSQL can pick an index scan if it is more efficient than a full table scan was already discussed. The following image shows the output of the tool, when dimension 0 (the first dimension) from 0 to 50000 in steps of 10000 is iterated and the query:
SELECT * FROM data WHERE key > ...;
was executed.
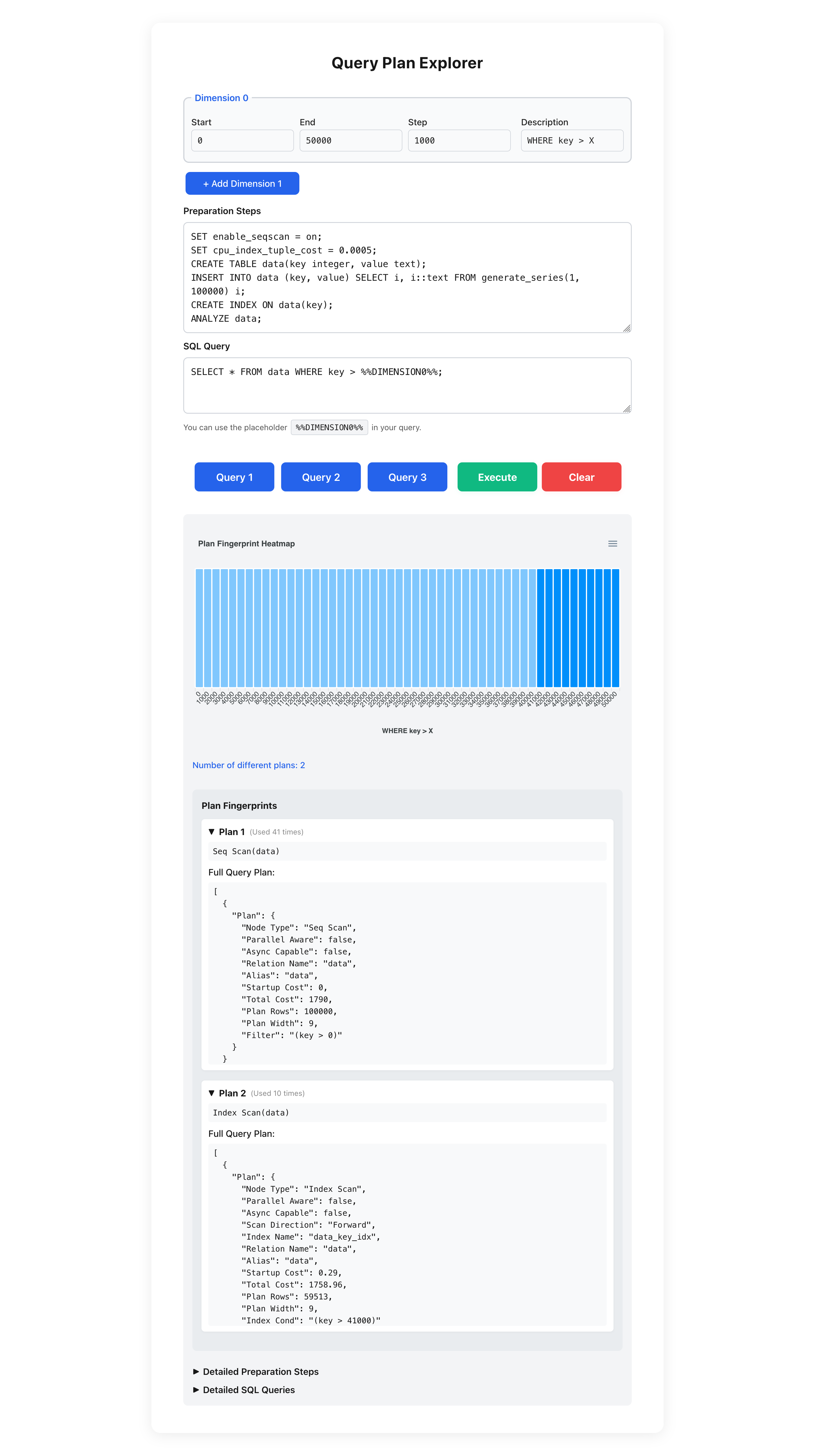
It can be seen in the produced image that after the value of 40000, the query plan changes (light blue vs. dark blue). This is also the expected behavior. When fewer tuples are returned by the query, it is beneficial to use the index.
Below is the visualization of the query plan, the actually used query plans are shown. The first one is the actual full table scan:
[
{
"Plan": {
"Node Type": "Seq Scan",
"Parallel Aware": false,
"Async Capable": false,
"Relation Name": "data",
"Alias": "data",
"Startup Cost": 0,
"Total Cost": 1790,
"Plan Rows": 100000,
"Plan Width": 9,
"Filter": "(key > 0)"
}
}
]
The second query plan is the index scan using the index on the key attribute.
[
{
"Plan": {
"Node Type": "Index Scan",
"Parallel Aware": false,
"Async Capable": false,
"Scan Direction": "Forward",
"Index Name": "data_key_idx",
"Relation Name": "data",
"Alias": "data",
"Startup Cost": 0.29,
"Total Cost": 1769.94,
"Plan Rows": 59896,
"Plan Width": 9,
"Index Cond": "(key > 40000)"
}
}
]
Changing the Random Page Costs
The next example shows when PostgreSQL changes from a table scan to an index scan as the selectivity of a predicate changes. A one-dimensional search space was used to execute the query.
However, the exact point at which PostgreSQL switches from one plan to another also depends on the set costs for page access. For instance, the setting random_page_cost has a default value of 4 and describes the costs that occur when a page is accessed in random order (in contrast to seq_page_cost with a default value of 1 when a page is accessed sequentially). In this experiment, the same query is performed, but a two-dimensional search space is used. The value for random_page_cost is changed from 0 to 8 in steps of 0.25. The result can be seen in the following image:

Light blue is again the query plan that uses the sequential (full table) scan and dark blue is the query plan that uses the index scan.
It can be seen that PostgreSQL uses the index scan much earlier when the random_page_cost is low (i.e., the penalty of following the pointers in the index and accessing pages in random order is lower). In contrast, when the random_page_cost is high, PostgreSQL starts to use the index scan much later.
Performing a Self-Join
The last example shows a more complex scenario with more than two different query plans. The example query now performs a self-join and has the same WHERE clause as the previous examples:
SET random_page_cost = %%DIMENSION1%%;
SELECT * FROM data d1 LEFT JOIN data d2 ON (d1.key = d2.key) WHERE d1.key > %%DIMENSION0%%;
Again, dimension 0 changes the selectivity of the WHERE clause and dimension 1 changes the random_page_cost.

The generated image shows that PostgreSQL now uses four different query plans to execute the query. Even in this new query, PostgreSQL can decide whether to use the index or not. Furthermore, the join order can be changed and further optimizations can be applied (however, the details will not be covered in this blog post).
Conclusion
I was able to build a modern web application that uses an in-browser version of PostgreSQL to visualize the query plans used for particular queries in just a few hours, despite having only minimal skills in modern web development. GitHub Copilot with GPT 4.1 did a very good job, and vibe coding really seems to be a viable approach for building simple web apps.
I definitely learned less than I would have by building this tool in plain React and reading all the needed tutorials. But I spent just a couple of hours on the problem and have a usable tool. Otherwise, this would have been a multi-week project and I would never have taken up this development.
The created tool is available at https://jnidzwetzki.github.io/planexplorer/ and could be used by the database (research) community to explore the generated query plans by PostgreSQL. It might also be a valuable tool for PostgreSQL extension developers who create their own operators and cost models and want to understand when a particular query plan is chosen by the query optimizer.